
Capital Media Co., Ltd. Tetsuji Narishige has developed and released a voice recognition system that implements parallel processing from multiple microphones. The recognized character string is displayed for each speaker in real time with the streaming video shot by the video camera.
■ Background
In many voice recognition systems, after removing noise from voice input such as conversation, features are extracted and characters are output by AI model. However, there was a problem that it was difficult to recognize when many people were talking at the same time. In this system, by processing and outputting the voice input from multiple microphones in parallel, it is possible to recognize the continuous voice input for each speaker with higher accuracy, and the extracted character string is also divided for each speaker. It is realized to display.
■ Speech recognition system for parallel processing of multiple microphones
In this system, the character string recognized by the voice microphone is dynamically displayed in any application in real time. By parallel processing with multiple microphones, recognition and output from multiple sound sources is possible. By creating a dictionary of individual terms, you can also recognize specific words with high accuracy. In addition to Japanese, English and Chinese (simplified characters) can be recognized, and the output text is also output in Japanese, English, and Chinese (simplified characters). We also support srt files.
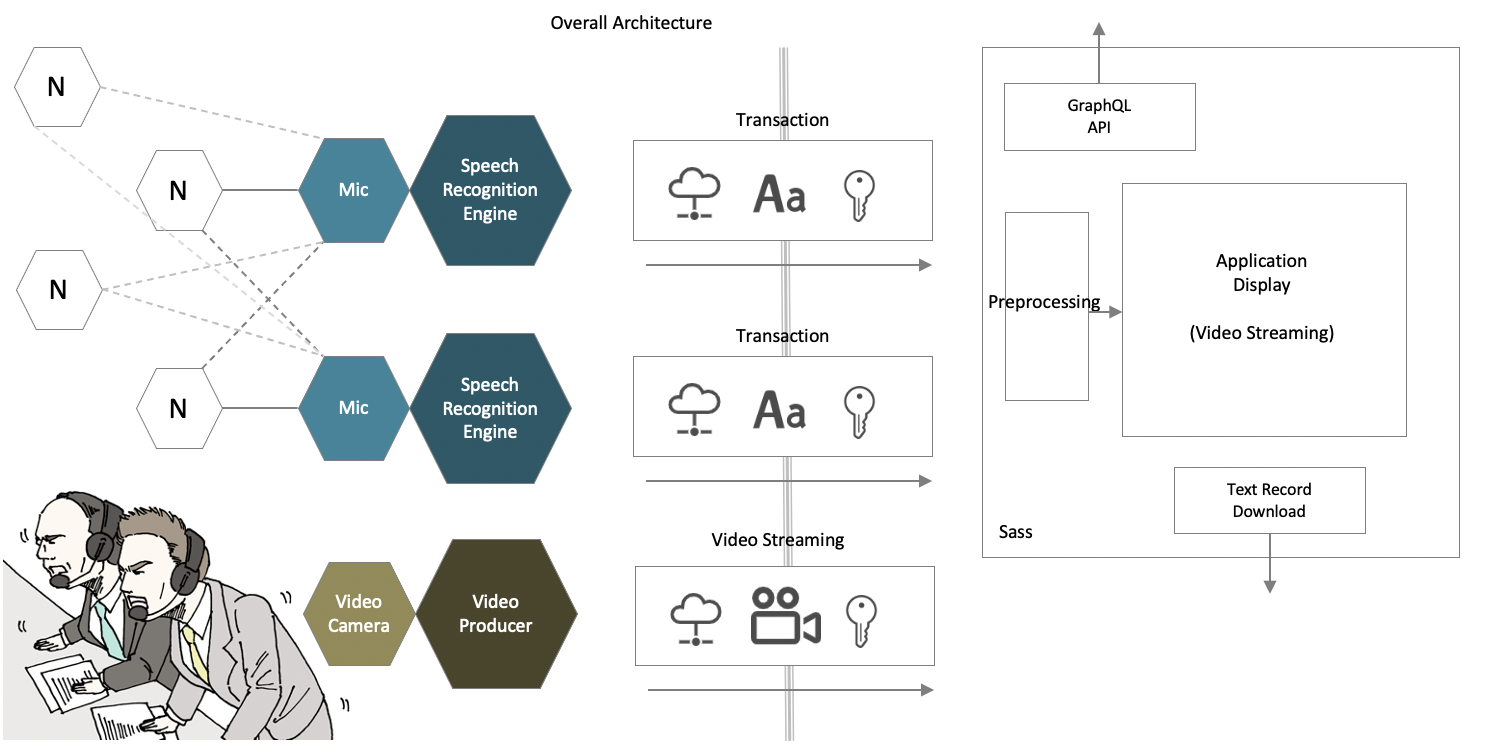
It is expected to be used for various purposes such as sports broadcasting, concert broadcasting, digital signage, conferences / seminars / interviews, call centers, vehicle driving operations, etc., and we will propose designs that meet the needs of client.
■About our development
We are researching more accurate speech recognition such as wav2vec2.0 using transformer. In addition, this system is being developed in GCP (Google Cloud Platform) environment with React.js, Go lang, Python, etc., and will continue to actively utilize modern technologies worldwide to contribute to solving corporate issues.
【Contact Us】
Capital Media, inc.
1-7-5, Minami Kamata, Ota-ku, Tokyo, 144-0035, Japan
E-mail: contact@capitalmedia.jp
https://capitalmedia.jp