
2021/07/26 15:00
Capital Media Co., Ltd.(代表董事:Tetsuji Narishige,以下简称“本公司”)开发并发布了实现多个麦克风并行处理的语音识别系统。根据摄像机拍摄的流媒体视频,为每个说话者实时显示识别出的字符串。
■背景
在许多语音识别系统中,从对话等语音输入中去除噪声后,通过人工智能模型提取特征并输出字符。但是,有一个问题,当许多人同时说话时,很难识别。在本系统中,通过对多个麦克风输入的语音进行并行处理输出,可以更准确地识别每个说话人连续输入的语音,提取的字符串也按每个说话人进行分割,实现显示.
■多麦克风并行处理语音识别系统
在该系统中,语音麦克风识别出的字符串实时动态显示在任何应用程序中。通过多个麦克风的并行处理,可以识别和输出多个声源。通过创建单个术语的词典,您还可以高精度地识别特定单词。除了日文,还可以识别英文和中文(简体字),输出文本也输出日文、英文和中文(简体字)。我们也支持 srt 文件。
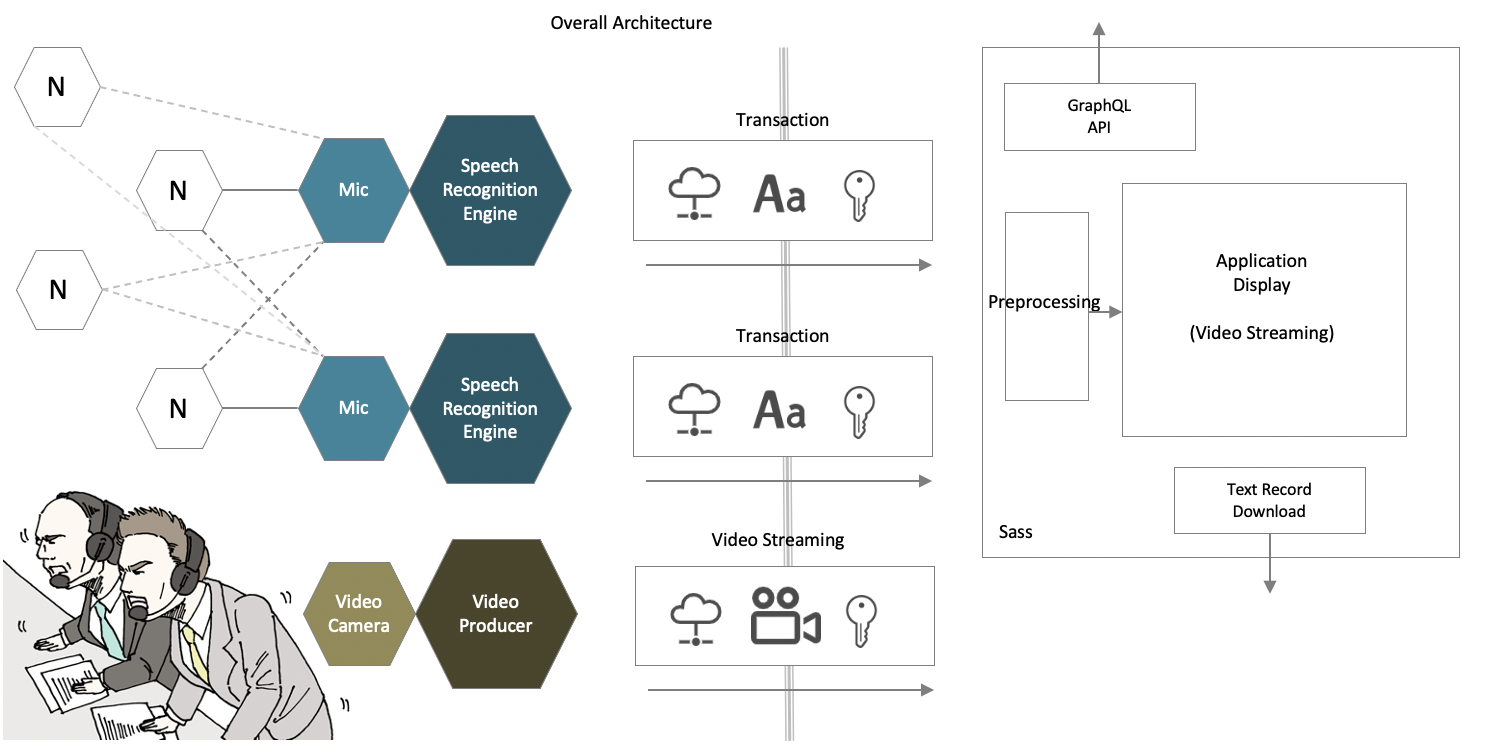
预计可用于体育广播、音乐会广播、数字标牌、会议/研讨会/采访、呼叫中心、车辆驾驶操作等各种用途,我们将提出满足客户需求的设计。
■关于我们的发展
我们正在研究使用 Transformer 的更准确的语音识别,例如 wav2vec2.0。另外,这个系统正在GCP(Google Cloud Platform)环境下使用React.js、Go语言、Python等进行开发,并将继续积极利用世界范围内的现代技术为解决企业问题做出贡献。我会继续做它。
[联系]
资本媒体株式会社
东京都大田区南蒲田南1-7-5
电话:03-3730-4850
电子邮件:contact@capitalmedia.jp
https://capitalmedia.jp